|
Email: wangduomin[at]gmail.com Google Scholar Github I am currently a senior researcher at Nvidia from 2025. My research interests include video generation, avatar synthesis and driving, embodied ai for robotics and world model. Before joining Nvidia, I was a senior researcher at Stepfun, working on video generation and agentic avatar. Before that, I was a researcher at Xiaobing for nearly three years, work closely with Yu Deng and Baoyuan Wang. Before that, I was worked at OPPO Research Institute for three years, my research results are applied to the camera software of OPPO mobile phones as the basic face algorithm.
I'm seeking research interns on embodied ai for robotics & world model. Feel free to send me an email if you are interested. Let's explore together how to leverage world models to create more possibilities for digital human interactions and physics robot. |

|
|
2025/09/09 We have open-sourced the UniVerse-1. Check it out here
2025/07/24 We have open-sourced the SpeakerVid-5M dataset and its data curation pipeline. Check it out here 2025/02/27 Had One paper accepted by CVPR 2025 about video prediction (MAGI). 2024/08/08 Had One paper accepted by ECCV 2024 workshop EEC about agent avatar (AgentAvatar). 2024/07/01 Had One paper accepted by ECCV 2024 about 4D avatar synthesis (Portrait4D-v2). 2024/02/27 Had two papers accepted by CVPR 2024, one is about 4D avatar synthesis (Portrait4D), the other one is about unconstrained virtural try-on (PICTURE). 2023/07/14 Had one paper accepted by ICCV 2023 about talking head sythesis (TH-PAD). 2023/07/10 Our CVPR 2023 work PD-FGC has released the code and model, check it out! 2023/02/28 Had one paper accepted by CVPR 2023 about talking head sythesis (PD-FGC). |


|
|
|
|
Peiwen Zhang, Yufan Deng, Shangkun Sun, Juncheng Ma, Duomin Wang, Jonas Du, Zilin Pan, Ye Huang, Hao Liang, Songyan Huang, Ruihua Zhang, Enze Xie, Ming-Yu Liu, Daquan Zhou arxiv, 2606.28128, [PDF] [Project] [Code] We propose PhysisForcing, a scalable training framework that strengthens physical consistency by focusing supervision on physics-informative regions through joint optimization of pixel-level and semantic-level features. |
|
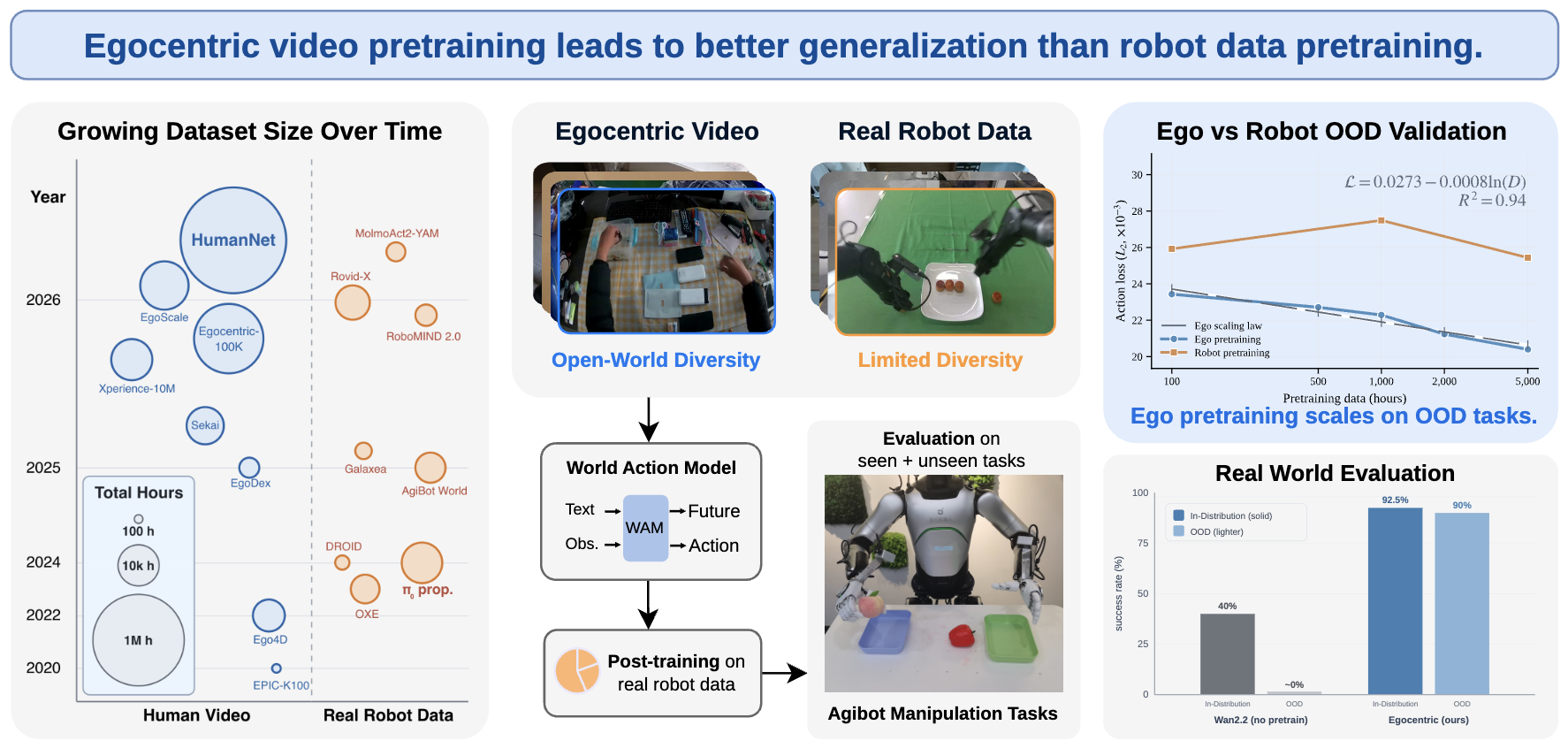
Juncheng Ma, Jianxin Bi, Yufan Deng, Xuanran Zhai, Kewei Zhang, Ye Huang, Bo Liang, Shukai Gong, Jiankai Tu, Xiaotian Tang, Jiaxin Li, Kaiqi Chen, Duomin Wang, Yuqi Wang, Bingyi Kang, Eric Huang, Zhiyang Dou, Zhen Dong, Enze Xie, Wojciech Matusik, Tat-Seng Chua, Daquan Zhou arxiv, 2606.20521, [PDF] [Project] With the same amount of pretraining data, models pretrained on egocentric data achieve a 24% lower validation loss on real-robot action prediction, as well as 52.5% and 90% higher success rates on in-distribution and out-of-distribution real-robot task execution, respectively. |
|
|
Ling-Hao Chen, Zixin Yin, Duomin Wang, Xianfang Zeng, Gang Yu ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques, ACM SIGGRAPH 2026, Oral Presentation [PDF] [Project] The first training-free cross-species motion transfer framework that models motion flow instead of skeletons, enabling motion transfer across diverse subjects such as human-to-panda directly at inference time. |
|
|
Duomin Wang, Wei Zuo, Aojie Li, Ling-Hao Chen, Xinyao Liao, Deyu Zhou, Zixin Yin, Xili Dai, Daxin Jiang, Gang Yu arXiv, 2509.06155, [PDF] [Project] [Code] [Model weights] [Verse-Bench] We introduce UniVerse-1, a unified, Veo-3-like model capable of simultaneously generating coordinated audio and video. To enhance training efficiency, we bypass training from scratch and instead employ a stitching of expertise technique. |

|
Zixin Yin, Xili Dai, Duomin Wang, Xianfang Zeng, Lionel M. Ni, Gang Yu, Heung-Yeung Shum The Fourteenth International Conference on Learning Representations, ICLR 2026, [PDF] [Project] LazyDrag, a drag-based image editing method for Multi-Modal Diffusion Transformers, eliminates implicit point matching, enabling precise geometric control and text guidance without test-time optimization. |

|
Zixin Yin, Xili Dai, Ling-Hao Chen, Deyu Zhou, Jianan Wang, Duomin Wang, Gang Yu, Lionel M. Ni, Lei Zhang, Heung-Yeung Shum The Fourteenth International Conference on Learning Representations, ICLR 2026, [PDF] [Project] We introduce ColorCtrl, a training-free method for text-guided color editing in images and videos. It enables precise, word-level control of color attributes while preserving geometry and material consistency. Experiments on SD3, FLUX.1-dev, and CogVideoX show that ColorCtrl outperforms existing training-free and commercial models, including GPT-4o and FLUX.1 Kontext Max, and generalizes well to instruction-based editing frameworks. |
|
|
Youliang Zhang, Zhaoyang Li, Duomin Wang, Jiahe Zhang, Deyu Zhou, Zixin Yin, Xili Dai, Gang Yu, Xiu Li The Fourteenth International Conference on Learning Representations, ICLR 2026, [PDF] [Project] [Code] [Dataset] We introduce SpeakerVid-5M, the first large-scale dataset designed specifically for the audio-visual dyadic interactive virtual human task |
|
|
Deyu Zhou, Quan Sun, Yuang Peng, Kun Yan, Runpei Dong, Duomin Wang, Zheng Ge, Nan Duan, Xiangyu Zhang, Lionel M. Ni, Heung-Yeung Shum IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2025, [PDF] [Project] [Code] We introduce MAGI, a hybrid video generation framework that combines masked modeling for intra-frame generation with causal modeling for next-frame generation. |
|
|
Yu Deng, Duomin Wang, Baoyuan Wang 2024 European Conference on Computer Vision, ECCV 2024, [PDF] [Project] [Code] We learn a lifelike 4D head synthesizer by creating pseudo multi-view videos from monocular ones as supervision. |
|
|
Shuliang Ning, Duomin Wang, Yipeng Qin, Zirong Jin, Baoyuan Wang, Xiaoguang Han 2024 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2024, [PDF] [Project] [Code] [BibTeX] we propose a novel virtual try-on from unconstrained designs (ucVTON) task to enable photorealistic synthesis of personalized composite clothing on input human image. |
|
|
Yu Deng, Duomin Wang, Xiaohang Ren, Xingyu Chen, Baoyuan Wang 2024 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2024, [PDF] [Project] [Code] [BibTeX] We propose a one-shot 4D head synthesis approach for high-fidelity 4D head avatar reconstruction while trained on large-scale synthetic data. |
|
|
Duomin Wang, Bin Dai, Yu Deng, Baoyuan Wang 2024 European Conference on Computer Vision, Workshop on EEC, ECCVW 2024, [PDF] [Project] [Code] [BibTeX] We introduce a system that harnesses LLMs to produce a series of detailed text descriptions of the avatar agents' facial motions and then pro- cessed by our task-agnostic driving engine into motion to- ken sequences, which are subsequently converted into con- tinuous motion embeddings that are further consumed by our standalone neural-based renderer to generate the fi- nal photorealistic avatar animations. |
|
|
Zhentao Yu, Zixin Yin, Deyu Zhou, Duomin Wang, Finn Wong, Baoyuan Wang 2023 IEEE International Conference on Computer Vision, ICCV 2023, [PDF] [Project] [Code(coming soon)] [BibTeX] We introduce a simple and novel framework for one-shot audio-driven talking head generation. Unlike prior works that require additional driving sources for controlled synthesis in a deterministic manner, we instead probabilistically sample all the holistic lip-irrelevant facial motions (i.e. pose, expression, blink, gaze, etc.) to semantically match the input audio while still maintaining both the photo-realism of audio-lip synchronization and the overall naturalness. |
|
|
Duomin Wang, Yu Deng, Zixin Yin, Heung-Yeung Shum, Baoyuan Wang 2023 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2023, [PDF] [Project] [Code] [BibTeX] We present a novel one-shot talking head synthesis method that achieves disentangled and fine-grained control over lip motion, eye gaze&blink, head pose, and emotional expression. We represent different motions via disentangled latent representations and leverage an image generator to synthesize talking heads from them. |
|
Conference Reviewer ICLR, WACV, NeurIPS, ACMMM, ICCV, CVPR.
|
|
The website template was adapted from Yu Deng. |